小学期回顾——大数据综合实践
前言
小学期作为我校工科的一项传统活动会被安排在每年春季学期结束后的两周,通常规定在两周时间内组队做一些项目or实验,需要投入相当多的时间和精力,此为背景
大一的小学期是C++程序设计实践,我过得充实而愉快;大二的小学期因为疫情的缘故而被取消了,实话说是有点遗憾;大三的小学期,也就是昨天刚结束的这次小学期(天,已经大三了,已经要毕业了,救……)围绕大数据技术展开。行到大三终于涉及大数据实践,仿佛是在文章结尾才出现题目的感觉,不过有比没有强!想到上个月找班主任签字聊到小学期安排点什么,我说也就分布式数据库算是沾了点大数据的边,像Spark、Scala啥的之前都没实战过,多少有点遗憾。没想到小学期全给安排上了🙏666
这当然依旧是过得充实而愉快的两周!甚至在开始之前我就已经非常期待了!感谢我的工程日记帮助我进行回顾,感谢老师在实验过程中的帮助和提示!当然,还得郑重感谢我的队友们:slave 1号2号3号5号以及编外 slave database 的积极配合!
Day1 —— 0712
小学期的第一天北京下了大暴雨,学院通知改成线上课。上课前一刻钟醒来,熟练地挂上腾讯会议,开始边听边写媒体大数据实验(不是不想认真听课!是期末作业没有写完!还不是为了快点写完好冲小学期!)
其实今天的内容还好,就是说明了一下小学期的任务:
- 在自己的电脑上使用虚拟机按实验指南搭建伪分布式环境( Hadoop + Spark + Zookeeper + Kafka )
- 六人左右在机房的电脑上搭建分布式环境,要求同上
- 词频统计
- 电影推荐模型训练和预测结果输出
- 社交网络分析
- 电影推荐流式处理版
鉴于暴雨不能出门机房也不开门,今天就做任务1:打开 VMware Workstation,打开虚拟机 …… 中午超市只剩下香菇炖鸡泡面,也 … 不是不能吃吧 …… 下午13:30,任务1✅
之后就去写玩具搜索引擎的前端了,想到之后在电影推荐任务还复用了这个界面,可以可以,我就喜欢废物利用
Day2 —— 0713
从今天起,小学期就正式开始了!
我把笔记本背出寝室的日子在本学期一只手都数得过来,没想到从今天起就要天天背了,no!!!
“一个人的命运啊,当然要靠自我奋斗,但也要考虑到历史的…… ”咳咳,于是我勇敢担下 master 节点的重担,但当时怎么也不会想到之后会被 slave 们讨伐,甚至大喊资本去4 ???
无论如何,在我自认还算高效的规划下很快确定了分工,开始搭建集群。中午啃完玉米后(别问我为什么这么频繁提到午饭吃了什么,本个体靠进食区分时段)五个节点的 Hadoop 集群就差不多搭完了,当然还连带上联网免密登录给 database 节点修 bug 这些小步骤……
下课之前(机房居然17点就赶人了,955,在互联网行业大概是很难有的待遇吧)搭完整个分布式环境,大概就干了这些,工程日记上多的也没写了
Day3 —— 0714
今天可以开始做实验了,早上早早来到机房( 指 08:55 ),美美启动集群开始整活
手打完实验指南的代码,一跑,诶?跑不通,于是拿出看家本领 —— 面向浏览器debug
缺库?装个 findspark
python 版本太高不兼容?emmm 有点棘手,先小降到3.7试试
在此,我必须反思一下:当我发现 spark2.4 和 Ubuntu 预装的 python3.8 存在不兼容后,随口告诉了对面的 slave4 ,导致了 slave4 的去世和 slave5 的诞生,以及 slave2 的半身不遂(sorry,语文太差只能找到这种词)。因为这两只 slave 直接卸载了 python3.8,对于卸载 Ubuntu 自带 python 的后果,依据我去年捣鼓家里旧电脑获得的经验是似乎只能重装……
1
2
3
4
5
6# 这里给出ubuntu修改python软连接的安全方法
# 首先,系统自带的python不要卸!直接下新的就行,多个python不会出事(不放心就上虚环境)
# 先看看/usr/bin下有没有python软链接,有就不要随便动了,多少换个名字,没有可以放心自己建
sudo ln -s /usr/bin/python3.7 /usr/bin/python # 建立python软链接,让python指向python3.7
sudo rm /usr/bin/python # 移除python软链接
sudo vim /usr/bin/pip # 在文件第一行可以修改pip指向的python如果还想在 Linux 上使用 Flask 服务器,由于 Linux 目录是可以含有.(对于隐藏文件),Flask 可能会抛出异常。当时求快直接注释了源码,回头想想这个做法并不妥当,还是在程序当中异常处理好一些
解决上述问题这个实验代码就能跑了。但是由于 slave 节点出了问题,匆匆保存实验结果之后就开始抢修集群
删去去世节点,加入新节点。一直到下课 Hadoop 集群都没修好,应该是我操作步骤有误,于是拿U盘拷了错误日志回去复盘。原本准备了3个解决方案(如下图 Debug 日志所示),想着要拿这个 bug 好好开开刀🔪

Day4 —— 0715
早上兴冲冲来到机房修 bug,好家伙,bug 变了?输出的错误日志和昨天说得完全不一样!心一横我就决定重装 Hadoop 集群,怎么说呢,毕竟还是重装最快,什么 baidu,google,stackoverflow,都不如重装!重装一下什么毛病都好了(生产环境当然不能这么干,我这不是 hdfs 里还啥也没有嘛,不耽误不耽误😅)
重装之后 database 节点也给我进集群干活,手里就这么几台破机子,都不许给我闲着!
集群正常工作后先往 hdfs 里导入所有实验需要的数据(作为 master 我还是很认真负责的!),然后开始跑下一个实验。中午边吃锅盔边改缩进:所有 slave !以后写代码都给我用 vim !( hhh开玩笑的,我不是万恶的资本家 )
改完缩进就能跑了,感!动!可惜集群上只能用小数据集,大数据集一跑就内存溢出。把优化的任务分配下去,然后开实验3(这里说明:由于人数不算多,采用扁平化管理,每个组员都可以直接和我沟通;每个子任务通常会安排两个人进行结对编程,加快效率;任务的分配比较灵活,会根据进度进行变更)
实验3这里由于不熟悉 spark 的使用,在提交 jar 包上踩了好大一个坑。先是发现使用 --package 参数由于网站被 ban 而无法自动下载,于是粗定了两个路线
- 阅读
spark-submit命令和 pyspark 的文档,研究 jar 包的其他提交方式 - 试图在机子上整个代理
Day5 —— 0716
被这个 jar 包的提交卡了很久,最后在老师的帮助下了解到直接 --jars 带上包的绝对路径就ok。后来总结了一下,pyspark 使用本地 jar 包大致可以有三种方法
spark-submit命令带上--jars参数(对于用逗号分割多个包暂时存疑,因为之后多个包提交的时候发现第二个包没提交上去)- pyspark 新建 spark 上下文时,使用
.set("spark.jars", "/xxx/xxx.jar") - 将 jar 包直接放在所有 spark 节点的
spark/jars目录下(可能会导致包之间的冲突,推荐使用前两种方法)
提交之后就可以查看 Spark 任务界面环境选项里所有的 jar 包以确认是否提交成功
jar 包成功提交之后又陷入因对 Dataframe 的操作不熟悉而无法将代码结果写入文件的问题,问题真是一套又一套啊!
下课后短暂规划了下周一交流学习汇报 Kafka 的任务分工(出于对这个名字的兴趣以及好找教材,在选择交流主题的时候毫不犹豫就拍板了 Kafka)
其实当天晚上还“开夜车”了,总之是一段痛苦的使用云平台大数据集群的经历,不提也罢
Day6 —— 0717
非工作日不上课。主要写媒体大数据期末论文来着,现学一点有关换脸算法的原理,什么三角剖分、仿射变换、泊松融合。幸运地找了当时参考代码原作者的教程视频 Select and Warp triangles - Face swapping Opencv with Python (part 4),一行行手打,一手知识!
Day7 —— 0718
非工作日不上课。学习Kafka!参考《Kafka权威指南》及官方文档。因为分配到的部分是流式处理:首先阅读前几章打基础梳理关键概念,之后快速过了一下每个章节,重点看了看感兴趣的点,然后直奔第11章流式处理
不得不说,流式处理确实是和我以前写过的请求与响应式处理方法很不一样。流式处理带给我最大的感受可以概括为时间和记录,或者这本来就是一种感受:日志
学习完数据库之后其实我对日志的感触是不怎么深的,平时建库用表也就直接导入数据读取数据这样用了,日志仿佛是学数据库原理时才会涉及的东西。但在流式处理中,日志流才是被处理的对象,表只是日志流变换带来的结果。流和表是从两个角度看待数据,不同角度在不同问题上的便利性不同。有时我们需要使用流的形式(比如对于需要基于时间窗口动态生成的数据),有时又需要使用表(当我们需要计算结果时,比如获取仓库的库存等等)
由表到流是很不方便的。这又让我想到多维空间的隐喻(感谢计组老师要求我们阅读《从一到无穷大》):流就好比时间束,而表则像是在一个时间点上对时间束的切片;我们每个人在每个时刻的状态是表,我们的人生轨迹是流;从状态得到流显然是不可能的(除非像数据库那样保存着日志),但从流却可以轻易地得到状态(语文太差,咱们得意忘言好吧,反正就是这么个意思)
Kafka 就是被设计用于保存日志的分布式日志系统(FLAG中的L第一次给我大厂的实感)。为了做一个有效的 pre (让愿意听的听众听懂并受益),我选择分析一个使用 Kafka 进行流式处理的应用实例:感谢纽约时报的这篇博文 Publishing with Apache Kafka at The New York Times,读者了解 Kafka 及流式处理的简单概念后应该就可以理解整篇博文,并加深对 Kafka 整体概念的理解。作为本组中收尾的内容,我认为是比较恰当的
Day8 —— 0719
周一的上午交流学习,了解了很多关于 Hadoop、Spark、RDD、Zookeeper 的知识(别问我,现在已经忘记了
之后继续解决 Dataframe 写入文件的问题。由于在集群上处理一次完整数据时间过长,分为两个方向加速问题的解决
- 减小数据集:从原数据集生成子集
- 构造输出格式,目前已知是嵌套的 Dataframe
最后在小组成员的合作之下两个方向都取得了圆满的结果,结合查找到的 .select 方法成功将处理结果输出。使用了 Python 脚本处理数据(这不是作弊!)然后用 Gephi 可视化了网络,顺便也给别的组安利了,Gephi 打钱 😋
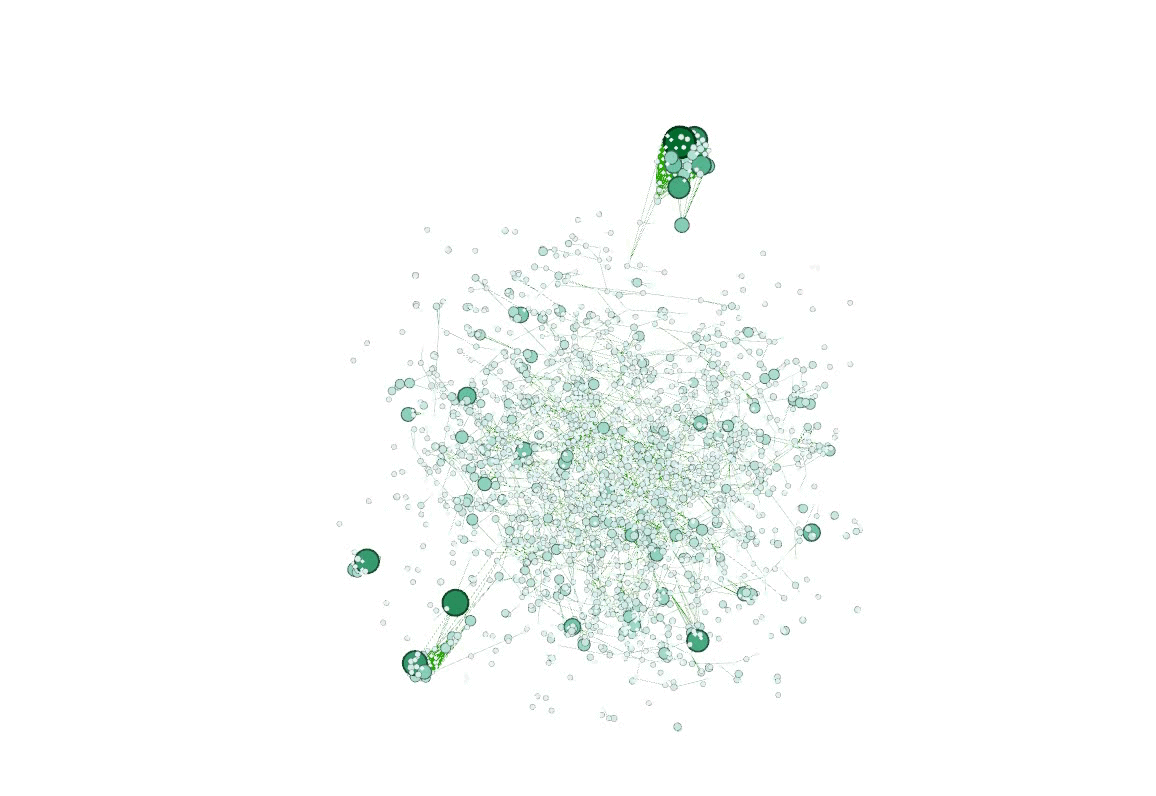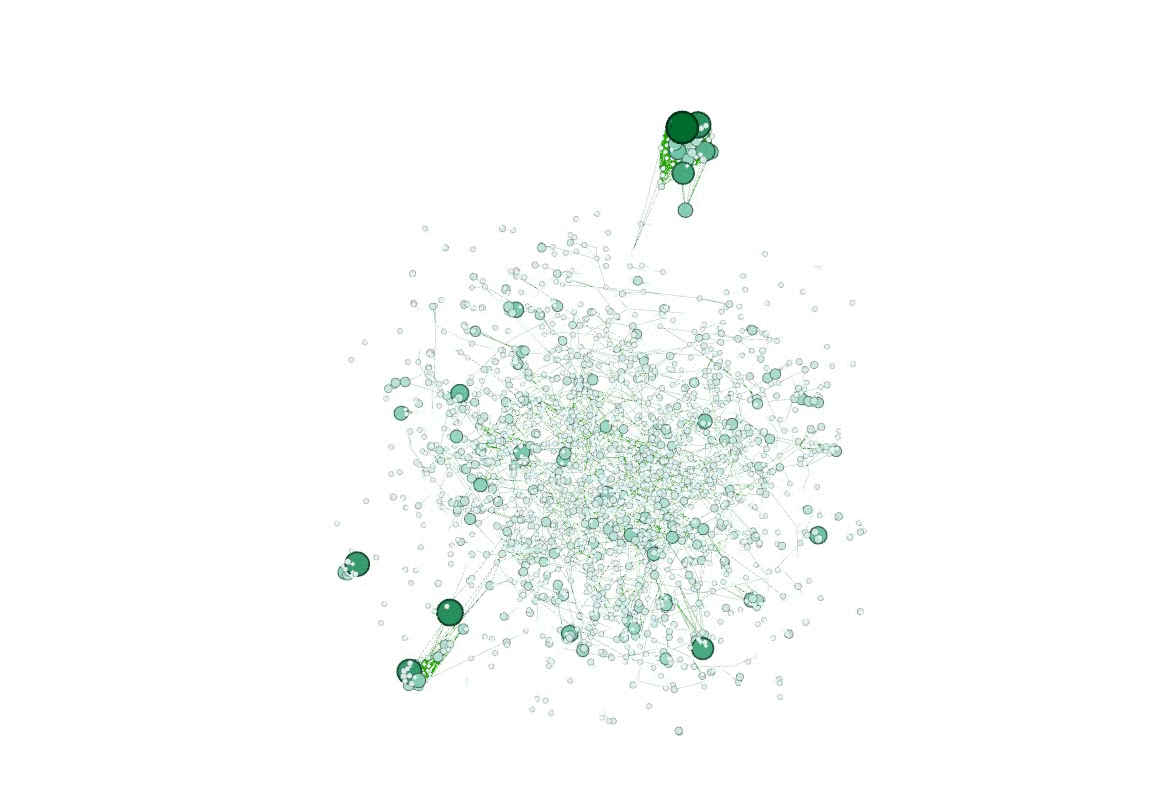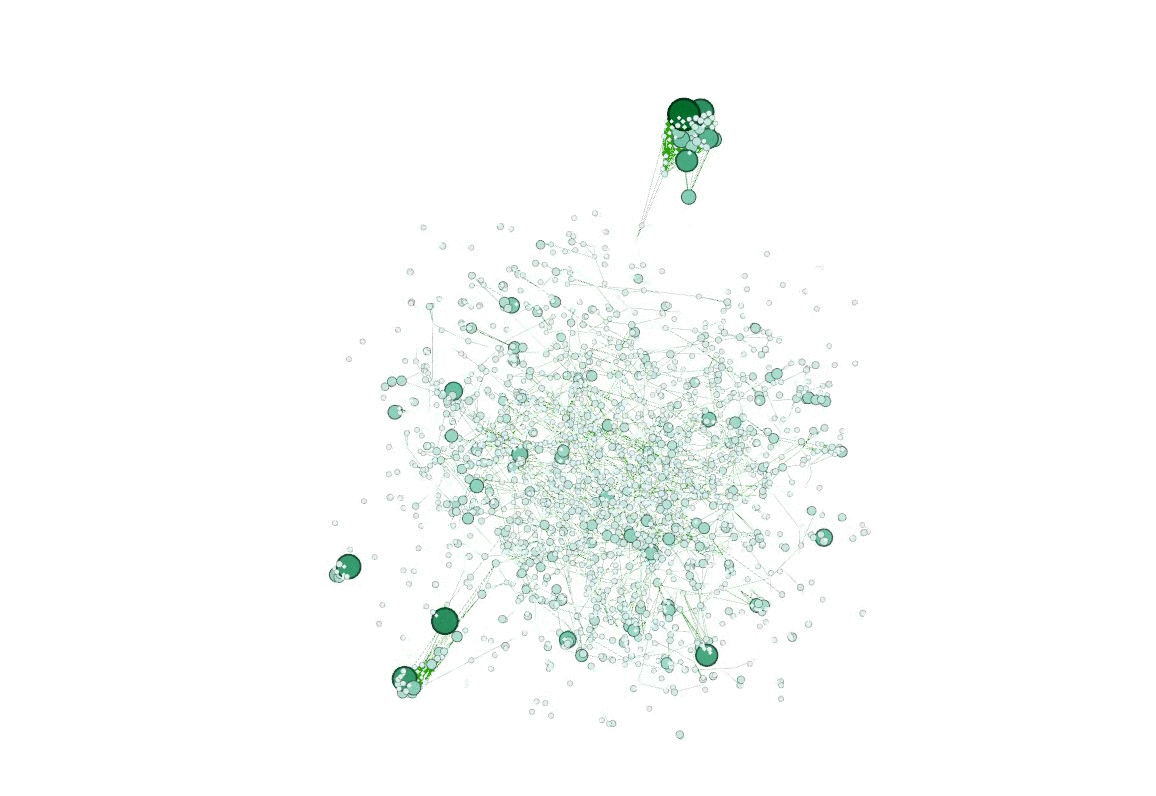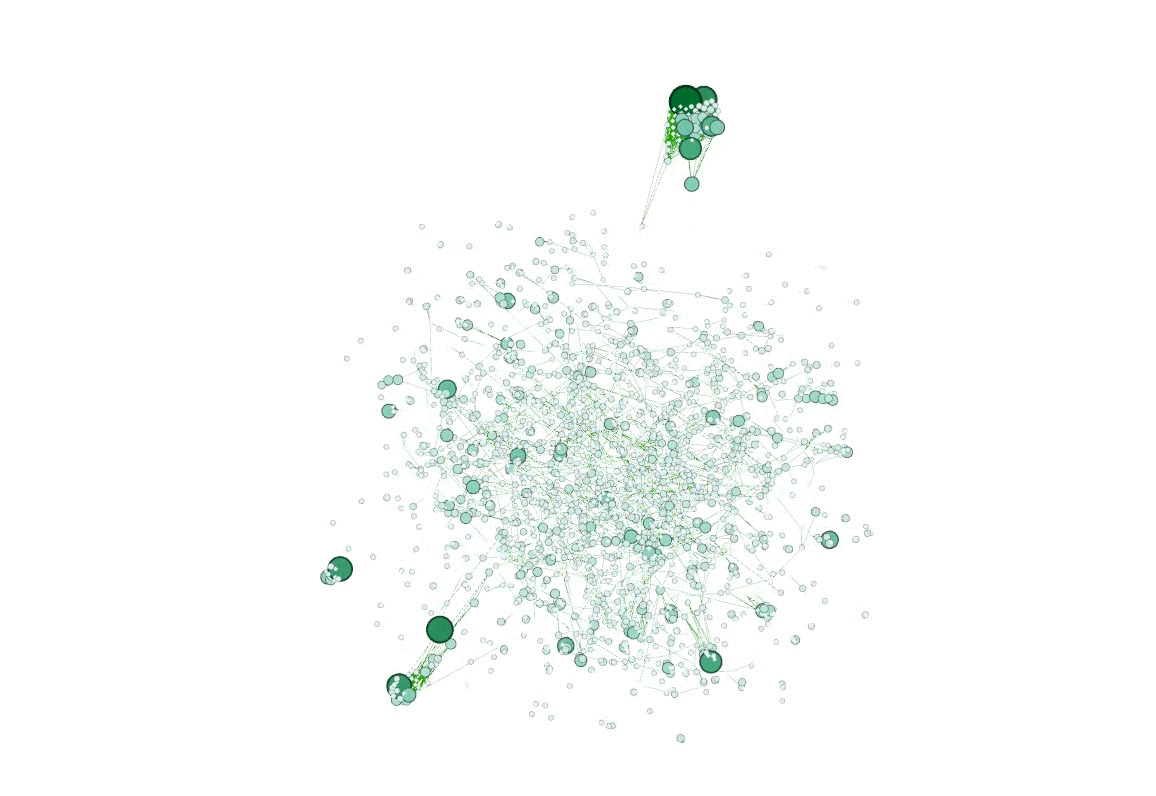
接着用 D3.js 力导向图可视化了最大连通子图。以前画力导向图的时候都直接用的默认 node 顺序,这次需要使用 index 到 id 的映射,为了找解决方案居然还卡了个把小时(感谢作者已然把源码封装地很好,仅仅是看了一眼源码我就放弃了暴力魔改源码的念头)。抱着作者既然在文档里提到这个问题就一定会留路子的想法最终在官网 demo 找到了需要的方法 .force("link", d3.forceLink(links).id(d => d.id))。这里默默吐槽在 stackoverflow 上看到的几个回答,也不知道是年代久远还是怎么回事,不仅没有提到这个方法,而且一致给出替代方案说让自己写映射函数……
Day9 —— 0720
今天一来先继续优化社交网络,把队友计算好的 PageRank 值和节点大小关联啥的
完成实验3之后想到周五下午就要答辩。鉴于后面两个实验是没有参考代码,时间肯定非常紧张,但还是不太想放弃后面两个实验中的任何一个(而且专攻一个也不一定能做完,再堆人完不成的还是完不成👋不如都做多学一点)。昨天下午已经抽空分配了高频共现词算法的调研工作,今天初见眉目,所以先让高频共现词小队继续复现 Apriori 算法;然后集合其余成员开始规划最后的流式处理实验
对于最后一个实验,我倾向于在有限时间内先挑重点突破。也即是说对于诸如前端页面设计,后端从数据库读数据,使用已保存模型预测结果等等常规的开发流程,由于以前或多或少都是实现过的,通通先放一边,重点放在使用Kafka进行流式处理上:
- 生成仿真数据写入Kafka
- 从Kafka读取仿真数据进行处理
- 将处理结果实时写入数据库
一方面让队友们将集群上的 Zookeeper 和 Kafka 节点联动正常工作;一方面着手在云平台上试验基础 API:Kafka Consumer
编辑完测试代码后很快发现云平台的 Kafka 集群似乎没有按预期设想工作,也无法登上节点查看错误日志。向老师报告问题后就将手头的代码移交 Kafka 小队,转而开始跟进高频共现词方面
Day10 —— 0721
今天开工前先简短组织了一下晨会,收集进度和分配任务(这可能是两周来唯一一次正式晨会hhh)
大致了解了一下当前进度,并规划了三个任务
- 答辩导向 —— 整理实验素材(词云图优化、保存生成模型等等)
- 实验导向 —— 高频共现词提交集群运行
- 实验导向 —— Kakfa生产者和消费者实现
大体上还是延续昨天的分工。因为 slave2 的 Python 存在比较棘手的毛病一时不好解决,就把 database 节点加进 Spark 集群代替它工作了。同时从头回顾了前几个实验,先做了一些完善工作:
- 为词云图更换停词表、一致小写
- 对社交网络节点按 PageRank 值排序等等
转到高频共现词:当时 Apriori 算法已经通过50行的小规模数据集测试。在听完原理说明后,我先写了一个简单脚本来切割多达 169,2082 行的大数据集以生成任意行数的测试数据集。按序测试渐增数据集时还遇到了一个小乌龙:原本好好运行的任务突然报了没有遇见过的 bug ,一查说是 jar 包冲突,让我们感到非常奇怪但又不敢贸然卸载 jar 包。最后发现是对面的 Kafka 小队使用 Spark Streaming 进行流式处理时需要使用 streaming-kafka-0-8-assembly_2.11-2.4.0.jar ,下载之后就直接分发到了集群的各个机器上导致包冲突(这也是我在 Day5 中写到不推荐第三种方法的原因)后来让 Kakfa 小队改用 --jars 跟随任务提交以避免包冲突
(对了,在集群上跑高频共现词的时候还出现了由于集群节点 Python 版本不一致而导致任务执行失败的情况,又是一通下载 Python 改 Python 指向。可能配好一个机子,其他直接用镜像是最好的)
Apriori 算法停滞在 1w 行就无法继续下去了(似乎还把集群跑挂了一回,master is unresponsive 谁懂!)在老师的提示下我们开始尝试官网提供的模型 Frequent Pattern Mining 。我继续转战云平台死磕 Apriori 算法;由 slave5 开始探索 FPG
Day11 —— 0722
上午基本是啥有用的也没干!光折腾暑假留校事项去了!
完事儿之后考虑到明天下午就要答辩,大家需要提前一点开始准备PPT什么的,实验方面就不怎么安排硬性任务了(工程日记到这也开始混乱起来,可以想见当时大约是有一、、忙碌)
按记忆下午似乎简短看了一下 PPT 制作进度;然后 Kafka 小队出现了消费者无法读消息的问题,于是开始 debug :输出了巨多中间结果,但始终报 RDD is empty。临下课求助老师,老师说他边发边读是ok的,我们一试果然如此!
slave5 那边的 FPG 算法出于性能考虑只能将结果直接输出。于是下课之后就有一堆💩一样的输出需要我格式化。打开 Jupyter Notebook ,上了一堆正则表达式终于切成能读的东西了

之后上云平台跑 FPG 算法,虽然自由度不高但性能是真没得说,从5万行一路到160多万行都成功处理了;洗完澡之后大致给 pre 打了个草稿顺便给已有的 PPT 刷了下格式
Day12 —— 0723
最后一天了!
昨天已经在 database 节点为流式处理实验建了一个新的 MySQL 用户,预备给 Kafka-python 用。上午主要和 slave2 一起解决把读取到的数据写入 MySQL 的问题,需要用到 mysql-connector-java-8.0.25.jar,也就是在这发现逗号分隔多包提交居然没有任何效果……
最终进度就到这了,没能完全做完还是稍稍有些遗憾,不过想做的部分还算是都做到了✌️
还有就是,没想到都最后一天了居然会中暑,边忍着头痛边准备pre可真是(;′⌒`)
总结🎉
最后一个小学期,也是大学最后一门课,大学过得可真快!
这次实验综合性真的还挺强的,别的不说,我熟练背诵的 Linux 命令又多了好几条……
再次给我的 slave 们点赞👍大家都非常给力,master 下班了,回归嗑学家老本行🤪还望大家小心行事,以免误伤